- Thu. Apr 25th, 2024
Latest Post
 Batter of the Year Luke Suess’s Phenomenal Performance Leads New Ulm Baseball to Victory
Batter of the Year Luke Suess’s Phenomenal Performance Leads New Ulm Baseball to Victory
 Collaboration with Dutch Company VDL Brings Positive Changes to Van Hool’s Business
Collaboration with Dutch Company VDL Brings Positive Changes to Van Hool’s Business
 Wearable Technology Improves Postural Ergonomics in Neurosurgical Procedures: A Pilot Study.
Wearable Technology Improves Postural Ergonomics in Neurosurgical Procedures: A Pilot Study.
 Finance Pros Feeling Optimistic About Global Economy Despite Risks and Challenges
Finance Pros Feeling Optimistic About Global Economy Despite Risks and Challenges
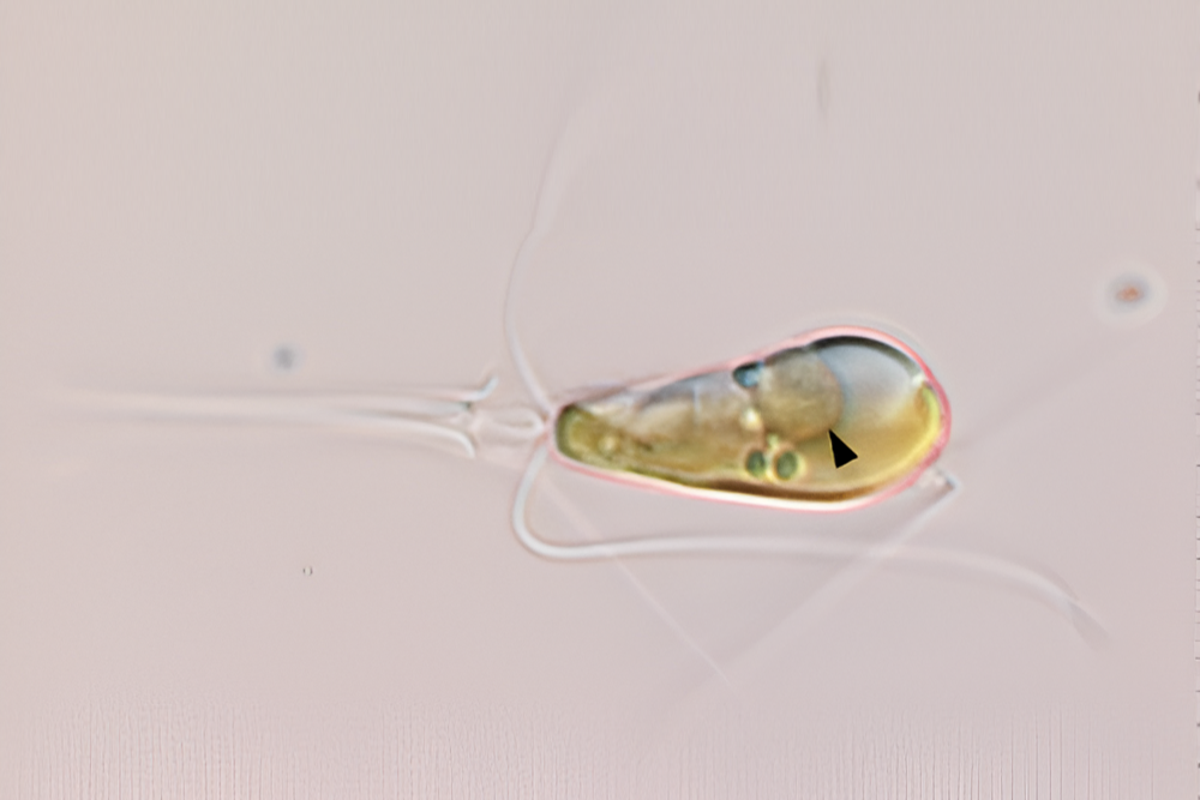 Scientists Observe Rare Evolutionary Event: Algae and Bacterium Merge to Form Single Organism
Scientists Observe Rare Evolutionary Event: Algae and Bacterium Merge to Form Single Organism
Batter of the Year Luke Suess’s Phenomenal Performance Leads New Ulm Baseball to Victory
New Ulm baseball’s victories against Worthington last Saturday were a result of the outstanding performance of Luke Suess. In both games, he had three hits, four RBIs, and scored two…
Collaboration with Dutch Company VDL Brings Positive Changes to Van Hool’s Business
The collaboration with Dutch company VDL is progressing positively, with a focus on bus activities rather than trailer production. This strategic decision indicates a clear direction for both companies as…
Wearable Technology Improves Postural Ergonomics in Neurosurgical Procedures: A Pilot Study.
A pilot study published in the Journal of Neurosurgery: Spine on April 19, 2024, explored the use of wearable technology to assess postural ergonomics and provide biofeedback to neurosurgeons. The…
Finance Pros Feeling Optimistic About Global Economy Despite Risks and Challenges
A recent study by ACCA and IMA has shown that finance professionals are feeling optimistic about the global economy. Despite concerns about increasing operating costs, confidence has risen and indicators…
Scientists Observe Rare Evolutionary Event: Algae and Bacterium Merge to Form Single Organism
Get the latest in opinions and stay informed with our Voices newsletter. For the first time in at least a billion years, two lifeforms have merged to form a single…
The Unusual Debate: Should German Workers Work More to Boost the Economy?
In recent years, German politicians and business leaders have started discussing a topic that was previously considered taboo: the idea that their fellow citizens do not work enough. This has…
LG Electronics Reported Strong Returns in TV Business Thanks to Streaming Services and Home Appliance Sales
In the first quarter of 2021, LG Electronics reported a return to profitability in its TV business thanks to the recovery of demand in Europe and the increasing popularity of…
Drones Take Flight in Miami Township: Enhancing Law Enforcement and Community Safety
Miami Township has seen a significant improvement in community safety and law enforcement capabilities thanks to the use of drones. Chief Mike Mills stated that the department has only been…
Providing Valuable Work Experience: Licking Heights Local Schools Launch High School Tech Internship Program Funded by Governor’s Office of Workforce Transformation
The High School Tech Internship program, funded by an investment from the Governor’s Office of Workforce Transformation, will provide real-life experience and on-the-job technology training for 10 high school students…
From Home Run to Movie Love: Kiah Helget’s Favorite Things
Kiah Helget, a senior at New Ulm Cathedral, hit a two-run home run against Nicollet on Monday at Harman Park, leading the Greyhounds to a 16-0 victory in just four…